

DeepSeek是一個由中國公司DeepSeek(深度求索)所開發的大型語言模型(LLM),DeepSeek 創立後不到一年就推出號稱與「ChatGPT」同等級的AI大語言模型,震撼美國矽谷也連讓AI相關公司股票市值蒸發19.7兆台幣,在輝達高階AI晶片限制賣到中國的情況下,DeepSeek如果是用少量的輝達低階GPU,只花558萬美金訓練成本,就能和主流大語言模型(LLM)平起平坐,的確是非常讓人震驚的發展成果。
什麼是大語言模型(LLM)?
大語言模型的英文是「Large Language Model,簡稱LLM」是一種人工智慧技術,專門用來理解和生成人類語言。你可以把它想像成一個超級聰明的「語言大師」,它透過閱讀大量的文字資料(例如書籍、文章、網站內容等)來學習語言的規則和知識。OpenAI GhatGPT、Google Gemini、DeepSeek…都是LLM。DeepSeek 是一家什麼公司?
深度求索(DeepSeek)是一間中國的人工智慧(AI)公司,成立於 2023 年,目標是打造「通用人工智慧」(AGI)。DeepSeek 專注於研發最先進的 AI 技術,特別是「自然語言處理」(NLP)和「深度學習」,AI技術可以讓機器理解人類語言、生成文字、進行對話,甚至解決更複雜的問題,像是聊天機器人、文本生成、語文翻譯、整理資料…。
Deepseek官方網站

DeepSeek 主要創新核心技術
DeepSeek 的技術核心是「大語言模型」(LLM),類似於 OpenAI 的 GPT 或 Google 的 BERT,但他們更專注於實現 AGI,讓 AI 變得更通用、更智能。這意味著他們的技術不僅能處理語言,未來還能應用在更多領域,比如醫療診斷、金融分析、教育輔助等,DeepSeek 為了讓電腦在處理大量資料時,能夠更省記憶體、更快運算,並且適合處理複雜的任務,比如長篇文章或多輪對話,所以使用了以下技術。
多頭注意力 Multi-head Latent Attention (MLA)
-
目標:讓電腦處理很長的文字時,減少記憶體的使用,並且加快處理速度。
-
方法:透過一種叫做「低秩因子分解(Low-Rank Factorization)」的技術,把需要記住的資料變小,這樣記憶體需求就降低了。例如,原本需要很多記憶體,現在可以減少30%。
-
應用:適合處理很長的文章或對話,比如法律文件或多輪對話。
混合專家(MoE)架構
-
目標:讓電腦在處理複雜任務時更有效率。
-
方法:DeepSeek 用了一種叫「混合專家模型」(MoE)的技術,簡單來說,就是讓電腦在處理任務時,不需要動用全部的資源,只啟動一部分來工作就好。舉個例子,DeepSeek 的 R1 模型雖然總共有 6710 億個參數(可以想像成它的「腦容量」很大),但每次處理任務時,只會用到其中大約 370 億個參數。
-
特點:這樣的好處是,電腦跑得更快,而且還更省電、更省錢。
FP8 高效能使用記憶體
-
目標:讓電腦在訓練模型時,減少記憶體使用並加快運算速度。
-
方法:DeepSeek 用了 FP8 混合精度訓練框架,這個技術比傳統的 FP16 和 FP32 更省記憶體,讓訓練和推理的速度更快、效率更高。
-
通訊優化:在多個 GPU 之間傳輸資料時,使用一種叫做「DualPipe」的技術,讓資料傳輸更順暢,減少等待時間,提升整體效率。
什麼是 AGI?
AGI是「人工通用智慧」的英文簡寫,全名為 Artificial General Intelligence,AGI就是讓 AI 像人類一樣聰明,能夠理解、學習並完成各種複雜任務,而不只是單一功能,AGI跟AI最大的分別就是AGI會像人一樣的思考,有人類的自我意識,AGI還在開發中,目前看到的都是AI只能完成某一些特定任務,像是文本生成、圖片生成、聲音生成、影片生成…。
DeepSeek- V3、DeepSeek- R1的比較
DeepSeek於2024年底發布全新AI大語言模型DeepSeek-R1、DeepSeek-V3,並在2025年1月發布DeepSeek-R1的聊天機器人程式,我們來比較一下eepSeek-R1、DeepSeek-V3的差異,R1用於推理任比較強,V3 則是對語言處理比較擅長。
DeepSeek- V3、DeepSeek- R1 的比較表
| 特性 | Deepseek-V3 | Deep Seek-R1 |
|---|---|---|
| 模型規模 | 總參數量671億(671B),MoE架構,每個taken激活370億(37B)參數 |
總參數量與V3差不多,類似Moe架構 |
| 創新技術 | Moe架構的效能提升,結合多階段的數據優化,大規模預先訓練 | 使用GRPO方式進行RL訓練,針對沒有微調的模型提升性能,改進了推理能力 |
| 性能表現 | 在MMLU-Pro、MATH500、GPQA-Diamon測試中持平或超越其他開源的AI模型 | 在推理能力與OpenAI-o1-1217差不多,特別是程式設計、數學、複雜推理表現特別突出。 |
| 訓練方法 | 採用強化學習(RL)、監督微調(SFT)、預先訓練用了14.8兆的文本進行預訓練。 | 採用多階段訓練模式,冷啟動微調,再使用強化學習(RL)、監督微調(SFT) |
| 訓練成本 | DeepSeek V3 更具成本效益,需要更少的 GPU 時間 | 訓練成本相對於DeepSeek V3比較高 |
| 應用功能 | 文本生成、語文理解、文字翻譯,適用於NLP任務 | 應用用在比較深度的一些推理任務,像是數學解題、程式碼撰寫、複雜問題分析 |
| 本地端架設 | 支援本地部署,有軟硬體配置說明。 | 支援本地部署,有軟硬體配置說明。 |
什麼是NLP?
NLP 的英文全名是 Natural Language Processing,也就是「自然語言處理」的意思!簡單來說,自然語言處理(NLP)是一種讓電腦能「讀懂」和「處理」人類語言的技術。現在,很多公司都有大量的文字和語音資料,像是電子郵件、簡訊、社群媒體貼文等等,NLP 就是幫助他們從這些資料中提取有用資訊的工具。
DeepSeek 跟 ChatGPT 有什麼不一樣?
DeepSeek 和 ChatGPT 都是超厲害的 AI 語言模型,但它們在開發背景、技術特點和應用場景上有些不同,以下是比較表。
DeepSeek、ChatGPT 比較表
| 項目 | DeepSeek | ChatGPT |
|---|---|---|
| 開發公司 | 深度求索(中國) | OpenAI(美國) |
| 成立時間 | 2023年 | 2015年 |
| 開發時間 | 較新,技術仍在快速發展中 | 較成熟,已經歷多個版本(GPT-1 到 GPT-4) |
| 開發成本 | 未公開,可能投入大量資源於 AGI 研究 | 數億美元(包括硬體、數據和研發) |
| 訓練成本 | 558萬美元(DeepSeek-V3) | 10 億美元(GPT-4o) |
| 目標 | 實現通用人工智慧(AGI) | 開發強大的自然語言生成模型 |
| 核心技術 | 深度學習、自然語言處理、多任務處理 | GPT架構(Generative Pre-trained Transformer) |
| 語言優勢 | 中文處理優化 | 英文處理優化 |
| 開源情況 | DeepSeek-R1(開源)、API(收費) | 舊模型(GPT-2)開源,新模型(GPT-3、GPT-4)閉源、API(收費) |
| 免費版 | 目前無明確免費版資訊 | 有免費版,但功能有限要排隊 |
| 付費版 | 價錢尚未公開,可能按使用量收費 | ChatGPT Plus:每月 20 美元(約 600 台幣) |
| API價錢 | 0.14 美元(輸入) | 2.5 美元(輸入) |
| 應用場景 | 多任務處理、專業領域問答、中文環境 | 文字生成、對話系統、英文環境 |
| 對話能力 | 強調多輪對話和複雜問題解決 | 擅長生成連貫、自然的對話內容 |
| 文本生成能力 | 支援中文文本生成,質量高 | 英文文本生成能力極強 |
| 翻譯能力 | 中文翻譯優化 | 英文翻譯優化 |
| 企業合作 | 可能專注於中國市場和企業合作 | 全球範圍內合作,企業應用廣泛 |
| 未來發展 | 專注於 AGI,目標是更通用的 AI | 持續優化語言模型,擴展應用場景 |
| 硬體需求 | 未公開,可能需高效能計算資源 | 需要大量 GPU 和高效能計算資源 |
| 數據來源 | 未公開,可能包含大量中文數據 | 來自網路文本、書籍、文章等多種來源 |
| 用戶評價 | 尚在發展中,用戶評價較少 | 全球用戶評價高,尤其英文用戶 |
DeepSeek 與其他LLM的評測
DeepSeek-R1 在訓練後期使用強化學習技術,就算只有很少的標註資料,也把模型的推理能力拉高不少,無論是算數學、寫程式,還是自然語言推理這些任務,它的表現都能跟 OpenAI 的 o1 正式版不相上下。
DeepSeek 與其他AI評測比較
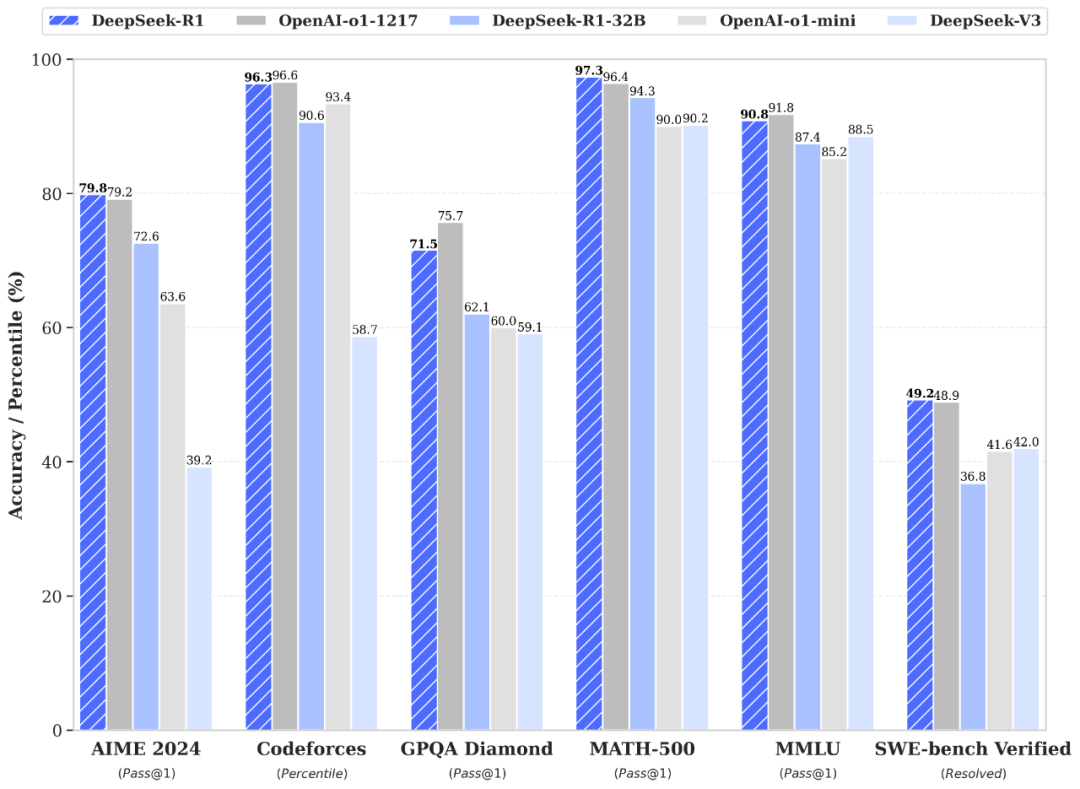
【圖片來源:https://api-docs.deepseek.com/】
DeepSeek API 要花多少錢?
來看看下面這張表,裡面列出的模型價格是以「百萬個 tokens」來算的。那什麼是 token 呢?簡單來說,token 就是模型處理文字的最小單位,可能是一個字、一個數字,甚至是一個標點符號。我們會根據你輸入和輸出的總 token 數來算錢,用多少算多少。
DeepSeek API 費用表
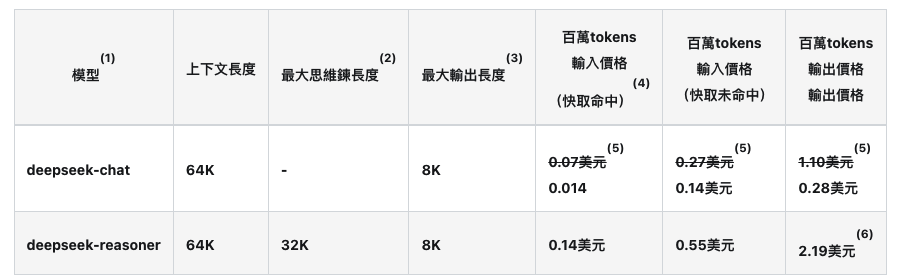
【資料來源:https://api-docs.deepseek.com/】
DeepSeek 的各種爭議
DeepSeek 是一家崛起很快的 AI 公司,技術和產品都很吸睛,但它在發展過程中也捲入了不少爭議,主要可以分成以下幾個爭議:抄襲風波
有人指控 DeepSeek 抄襲 OpenAI 的 GPT-3.5 模型,說他們用了「蒸餾」技術,從 ChatGPT 取材來訓練自己的模型,違反了 OpenAI 的使用規定。不過 DeepSeek 一直否認這些指控,堅稱他們的模型是自己獨立開發的。資料來源疑雲
有報導指出 DeepSeek 在訓練模型時用了大量未經授權的網路資料,這讓人擔心可能會涉及版權問題。更有指控說他們甚至拿其他 AI 模型的輸出來當作訓練資料,這在業界引起了不少討論。安全隱患
DeepSeek 的產品(像是 DeepSeek Chat)也被認為存在安全問題。有研究發現,這個聊天機器人有時會生成帶有歧視、暴力等不當內容。另外,他們的資料收集和使用方式也引發了不少疑慮,讓不少人擔心用戶隱私會不小心被洩露。政治與地區限制
作為一家中國公司,DeepSeek 的產品在某些國家和地區還遇到了限制。舉例來說,台灣當局禁止公務機關使用 DeepSeek 的 AI 產品,理由是擔心資料外洩和安全問題。同時,一些國家也限制 DeepSeek 在本地的服務,這也讓爭議持續發酵。
什麼是 DeepSeek 開源?
DeepSeek 開源的意意思就是深度求索(DeepSeek)把他們的一些技術或軟體程式碼公開出來,讓大家都可以自由查看、使用、修改,甚至分享給別人。這種做法就像是把技術的「秘方」公開,讓所有人都能參與進來,一起改進和創新。這樣不僅能讓技術進步得更快,還能讓知識更容易傳播出去。通過開源,DeepSeek不只是展示自己的技術有多厲害,還幫助了整個人工智能和機器學習領域的發展。開源的東西可能是一些算法、工具庫,或者是開發框架,這些東西對開發者來說超級有用,可以讓他們省去很多重複的工作,更快地把想法變成現實。而且,開源還有一個好處,就是能讓大家更信任這些技術。因為程式碼公開了,誰都可以檢查它的質量、安全性,甚至是否符合規範,這對企業來說特別重要。同時,開源還能吸引更多厲害的人加入,大家一起合作,整個行業就會變得更好。DeepSeek 開源「就是他們對技術共享和開放創新的一種方式」,希望通過大家的力量,讓人工智能技術變得更普及、更先進。如何使用 DeepSeek?
目前可以在網站使用,如同使用ChatGPT一樣,也可以去APP Store、Google Play搜尋『DeepSeek』下載APP安裝到行動裝置中使用。【DeepSeek網站版:https://chat.deepseek.com/】
對 SEO 有什麼影響?
AI對SEO影響非常大,無論實質上的執行,或是資料被AI機器人引用都跟AI有非常緊密的影響,之前都是英文為主的AI大語言模型,所以在語意上的處理還是有不少的缺陷,如果DeepSeek是以國際為市場,並保持數據開放,當然前提是不能被限制,我們對DeepSeek是抱持樂觀看待的。〈延伸閱讀:SEO如何用AI執行? AI演算法、AI工具實用攻略〉
對網站設計有什麼影響?
目前的網站設計的、AI應用比較多的就是圖片生成、AI挑圖、文案生成,網站設計生成還沒有很成熟,DeepSeek還沒有圖片生成,應用上只有文案生成可以用看看,其他都還要看未來的發展。〈延伸閱讀:網頁設計公司不會告訴你的5個真相〉
對AI市場有什麼影響?
目前的AI市場大部分都是幾家大廠的大語言模型(LLM)像是OpenAI GhatGPT、Google Gemini、Anthropic、Meta、Microsoft,少數幾家開源AI公司 Hugging Face、Stability AI、EleutherAI,中國市場AI有百度、阿里巴巴、騰訊、華為,DeepSeek的出現無疑是打破OpenAI 、Google 、Meta、Microsoft 的高成本規則,將AI帶入一個高CP值的市場如果真的是採用開源模式,那麼DeepSeek將因為低價而搶下不少市場佔比,對使用AI的企業與個人來說,成本降低絕對是一件好事,當然目前都只是推測,就讓我們繼續看下去吧。結論
DeepSeek的出現無疑為中文AI應用開啟另一道門,在現有的AI應用下有機會取代OpenAI的大語言模型,但因為剛出來不久評價和商業模式還不明確,各大LLM都不能忽視DeepSeek的出現,DeepSeek的爭議包含抄襲、資料、安全和政治等方面,不僅影響了DeepSeek 聲譽,DeepSeek需要更積極面對這些爭議,加強技術研發,提高產品安全性,並遵守相關法律法規,才能在競爭激烈的 AI 市場中立足。AI市場競爭越激烈,受益者肯定是使用AI的企業跟個人,不妨正面看待AI市場競爭與發展,停看聽才是企業的最佳策略。〈延伸閱讀:寫文案用ChatGPT好嗎?AI為SEO帶來什麼影響?〉
(本文為達文西數位科技所有,禁止轉載圖文)

