
DeepSeek是一个由中国公司DeepSeek(深度求索)所开发的大型语言模型(LLM),DeepSeek 创立后不到一年就推出号称与「ChatGPT」同等级的AI大语言模型,震撼美国矽谷也连让AI相关公司股票市值蒸发19.7兆台币,在辉达高阶AI晶片限制卖到中国的情况下,DeepSeek如果是用少量的辉达低阶GPU,只花558万美金训练成本,就能和主流大语言模型(LLM)平起平坐,的确是非常让人震惊的发展成果。
什么是大语言模型(LLM)?
大语言模型的英文是「Large Language Model,简称LLM」是一种人工智慧技术,专门用来理解和生成人类语言。你可以把它想像成一个超级聪明的「语言大师」,它透过阅读大量的文字资料(例如书籍、文章、网站内容等)来学习语言的规则和知识。 OpenAI GhatGPT、Google Gemini、DeepSeek…都是LLM。DeepSeek 是一家什么公司?
深度求索(DeepSeek)是一间中国的人工智慧(AI)公司,成立于 2023 年,目标是打造「通用人工智慧」(AGI)。 DeepSeek 专注于研发最先进的AI 技术,特别是「自然语言处理」(NLP)和「深度学习」,AI技术可以让机器理解人类语言、生成文字、进行对话,甚至解决更复杂的问题,像是聊天机器人、文本生成、语文翻译、整理资料…。
Deepseek官方网站

DeepSeek 主要创新核心技术
DeepSeek 的技术核心是「大语言模型」(LLM),类似于 OpenAI 的 GPT 或 Google 的 BERT,但他们更专注于实现 AGI,让 AI 变得更通用、更智能。这意味着他们的技术不仅能处理语言,未来还能应用在更多领域,比如医疗诊断、金融分析、教育辅助等,DeepSeek 为了让电脑在处理大量资料时,能够更省记忆体、更快运算,并且适合处理复杂的任务,比如长篇文章或多轮对话,所以使用了以下技术。
多头注意力 Multi-head Latent Attention (MLA)
-
目标:让电脑处理很长的文字时,减少记忆体的使用,并且加快处理速度。
-
方法:透过一种叫做「低秩因子分解(Low-Rank Factorization)」的技术,把需要记住的资料变小,这样记忆体需求就降低了。例如,原本需要很多记忆体,现在可以减少30%。
-
应用:适合处理很长的文章或对话,比如法律文件或多轮对话。
混合专家(MoE)架构
-
目标:让电脑在处理复杂任务时更有效率。
-
方法:DeepSeek 用了一种叫「混合专家模型」(MoE)的技术,简单来说,就是让电脑在处理任务时,不需要动用全部的资源,只启动一部分来工作就好。举个例子,DeepSeek 的 R1 模型虽然总共有 6710 亿个参数(可以想像成它的「脑容量」很大),但每次处理任务时,只会用到其中大约 370 亿个参数。
-
特点:这样的好处是,电脑跑得更快,而且还更省电、更省钱。
FP8 高效能使用记忆体
-
目标:让电脑在训练模型时,减少记忆体使用并加快运算速度。
-
方法:DeepSeek 用了 FP8 混合精度训练框架,这个技术比传统的 FP16 和 FP32 更省记忆体,让训练和推理的速度更快、效率更高。
-
通讯优化:在多个 GPU 之间传输资料时,使用一种叫做「DualPipe」的技术,让资料传输更顺畅,减少等待时间,提升整体效率。
什么是 AGI?
AGI是「人工通用智慧」的英文简写,全名为Artificial General Intelligence,AGI就是让AI 像人类一样聪明,能够理解、学习并完成各种复杂任务,而不只是单一功能,AGI跟AI最大的分别就是AGI会像人一样的思考,有人类的自我意识,AGI还在开发中,目前看到的都是AI只能完成某一些特定任务,像是文本生成、图片生成、声音生成、影片生成… 。DeepSeek- V3、DeepSeek- R1的比较
DeepSeek于2024年底发布全新AI大语言模型DeepSeek-R1、DeepSeek-V3,并在2025年1月发布DeepSeek-R1的聊天机器人程式,我们来比较一下eepSeek-R1、DeepSeek-V3的差异,R1用于推理任比较强,V3 则是对语言处理比较擅长。
DeepSeek- V3、DeepSeek- R1 的比较表
| 特性 | Deepseek-V3 | Deep Seek-R1 |
|---|---|---|
| 模型规模 | 总参数量671亿(671B),MoE架构,每个taken激活370亿(37B)参数 |
总参数量与V3差不多,类似Moe架构 |
| 创新技术 | Moe架构的效能提升,结合多阶段的数据优化,大规模预先训练 | 使用GRPO方式进行RL训练,针对没有微调的模型提升性能,改进了推理能力 |
| 性能表现 | 在MMLU-Pro、MATH500、GPQA-Diamon测试中持平或超越其他开源的AI模型 | 在推理能力与OpenAI-o1-1217差不多,特别是程式设计、数学、复杂推理表现特别突出。 |
| 训练方法 | 采用强化学习(RL)、监督微调(SFT)、预先训练用了14.8兆的文本进行预训练。 | 采用多阶段训练模式,冷启动微调,再使用强化学习(RL)、监督微调(SFT) |
| 训练成本 | DeepSeek V3 更具成本效益,需要更少的 GPU 时间 | 训练成本相对于DeepSeek V3比较高 |
| 应用功能 | 文本生成、语文理解、文字翻译,适用于NLP任务 | 应用用在比较深度的一些推理任务,像是数学解题、程式码撰写、复杂问题分析 |
| 本地端架设 | 支援本地部署,有软硬体配置说明。 | 支援本地部署,有软硬体配置说明。 |
什么是NLP?
NLP 的英文全名是 Natural Language Processing,也就是「自然语言处理」的意思!简单来说,自然语言处理(NLP)是一种让电脑能「读懂」和「处理」人类语言的技术。现在,很多公司都有大量的文字和语音资料,像是电子邮件、简讯、社群媒体贴文等等,NLP 就是帮助他们从这些资料中提取有用资讯的工具。
DeepSeek 跟 ChatGPT 有什么不一样?
DeepSeek 和 ChatGPT 都是超厉害的 AI 语言模型,但它们在开发背景、技术特点和应用场景上有些不同,以下是比较表。DeepSeek、ChatGPT 比较表
| 项目 | DeepSeek | ChatGPT |
|---|---|---|
| 开发公司 | 深度求索(中国) | OpenAI(美国) |
| 成立时间 | 2023年 | 2015年 |
| 开发时间 | 较新,技术仍在快速发展中 | 较成熟,已迭代多个版本(GPT-1 到 GPT-4) |
| 开发成本 | 未公开,可能投入大量资源于 AGI 研究 | 数亿美元(包括硬体、数据和研发) |
| 训练成本 | 558万美元(DeepSeek-V3) | 10 亿美元(GPT-4o) |
| 目标 | 实现通用人工智慧(AGI) | 开发强大的自然语言生成模型 |
| 核心技术 | 深度学习、自然语言处理、多任务处理 | GPT架构(Generative Pre-trained Transformer) |
| 语言优势 | 中文处理优化 | 英文处理优化 |
| 开源情况 | DeepSeek-R1(开源)、API(收费) | 旧模型(GPT-2)开源,新模型(GPT-3、GPT-4)闭源、API(收费) |
| 免费版 | 目前无明确免费版资讯 | 有免费版,但功能有限要排队 |
| 付费版 | 价钱尚未公开,可能按使用量收费 | ChatGPT Plus:每月 20 美元(约 600 台币) |
| API价钱 | 0.14 美元(输入) | 2.5 美元(输入) |
| 应用场景 | 多任务处理、专业领域问答、中文环境 | 文字生成、对话系统、英文环境 |
| 对话能力 | 强调多轮对话和复杂问题解决 | 擅长生成连贯、自然的对话内容 |
| 文本生成能力 | 支援中文文本生成,质量高 | 英文文本生成能力极强 |
| 翻译能力 | 中文翻译优化 | 英文翻译优化 |
| 企业合作 | 可能专注于中国市场和企业合作 | 全球范围内合作,企业应用广泛 |
| 未来发展 | 专注于 AGI,目标是更通用的 AI | 持续优化语言模型,扩展应用场景 |
| 硬体需求 | 未公开,可能需高效能计算资源 | 需要大量 GPU 和高效能计算资源 |
| 数据来源 | 未公开,可能包含大量中文数据 | 来自网路文本、书籍、文章等多种来源 |
| 用户评价 | 尚在发展中,用户评价较少 | 全球用户评价高,尤其英文用户 |
DeepSeek 与其他LLM的评测
DeepSeek-R1 在训练后期使用强化学习技术,就算只有很少的标注资料,也把模型的推理能力拉高不少,无论是算数学、写程式,还是自然语言推理这些任务,它的表现都能跟OpenAI 的o1 正式版不相上下。
DeepSeek 与其他AI评测比较
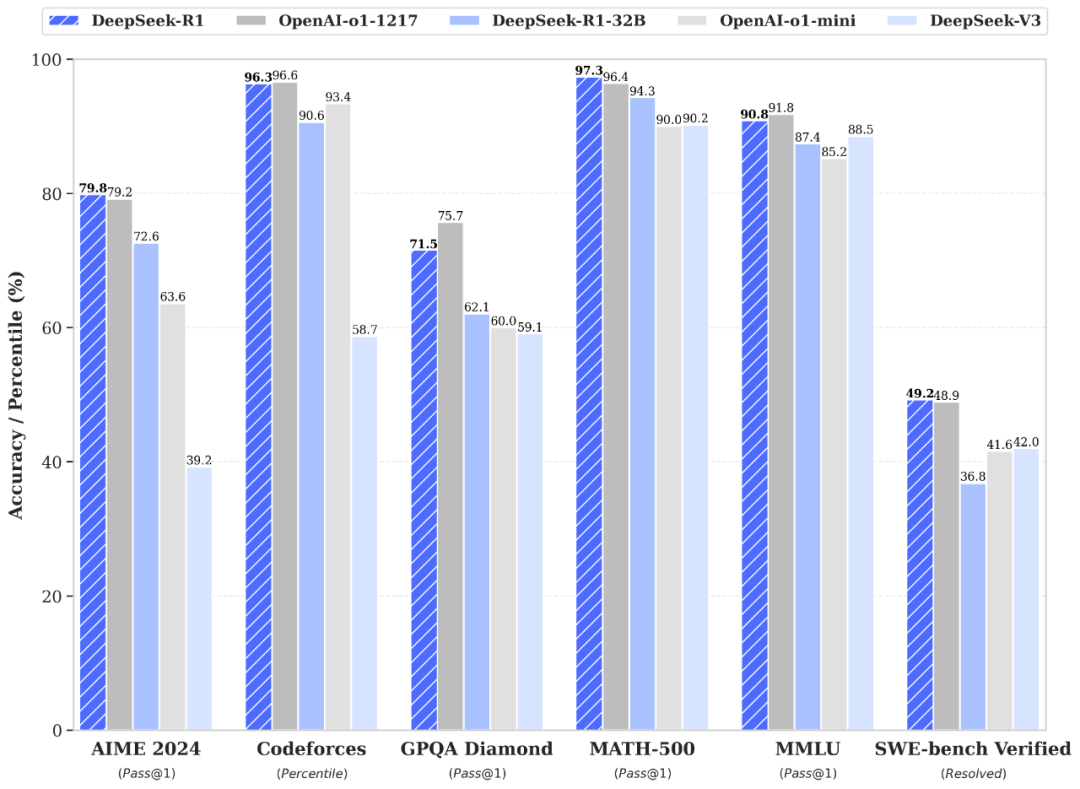
【图片来源:https://api-docs.deepseek.com/】
DeepSeek API 要花多少钱?
来看看下面这张表,里面列出的模型价格是以「百万个 tokens」来算的。 那什么是 token 呢?简单来说,token 就是模型处理文字的最小单位,可能是一个字、一个数字,甚至是一个标点符号。我们会根据你输入和输出的总 token 数来算钱,用多少算多少。
DeepSeek API 费用表
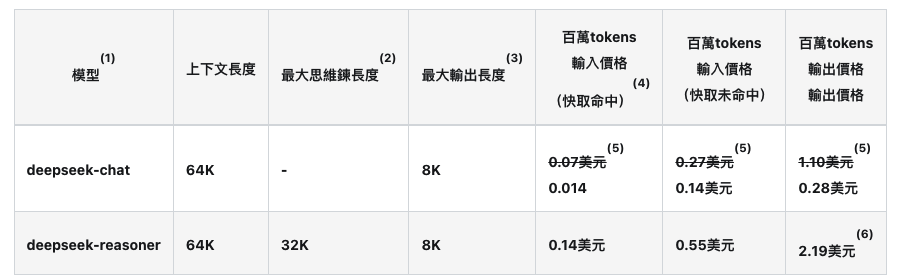
【资料来源:https://api-docs.deepseek.com/】
DeepSeek 的各种争议
DeepSeek 是一家崛起很快的 AI 公司,技术和产品都很吸睛,但它在发展过程中也卷入了不少争议,主要可以分成以下几个争议:抄袭风波
有人指控 DeepSeek 抄袭 OpenAI 的 GPT-3.5 模型,说他们用了「蒸馏」技术,从 ChatGPT 取材来训练自己的模型,违反了 OpenAI 的使用规定。不过 DeepSeek 一直否认这些指控,坚称他们的模型是自己独立开发的。资料来源疑云
有报导指出 DeepSeek 在训练模型时用了大量未经授权的网路资料,这让人担心可能会涉及版权问题。更有指控说他们甚至拿其他 AI 模型的输出来当作训练资料,这在业界引起了不少讨论。安全隐患
DeepSeek 的产品(像是 DeepSeek Chat)也被认为存在安全问题。有研究发现,这个聊天机器人有时会生成带有歧视、暴力等不当内容。另外,他们的资料收集和使用方式也引发了不少疑虑,让不少人担心用户隐私会不小心被泄露。政治与地区限制
作为一家中国公司,DeepSeek 的产品在某些国家和地区还遇到了限制。举例来说,台湾当局禁止公务机关使用 DeepSeek 的 AI 产品,理由是担心资料外泄和安全问题。同时,一些国家也限制 DeepSeek 在本地的服务,这也让争议持续发酵。如何使用 DeepSeek?
目前可以在网站使用,如同使用ChatGPT一样,也可以去APP Store、Google Play搜寻『DeepSeek』下载APP安装到行动装置中使用。【DeepSeek网站版:https://chat.deepseek.com/】< br />
对 SEO 有什么影响?
AI对SEO影响非常大,无论实质上的执行,或是资料被AI机器人引用都跟AI有非常紧密的影响,之前都是英文为主的AI大语言模型,所以在语意上的处理还是有不少的缺陷,如果DeepSeek是以国际为市场,并保持数据开放,当然前提是不能被限制,我们对DeepSeek是抱持乐观看待的。〈延伸阅读:SEO如何用AI执行? AI演算法、AI工具实用攻略〉
对网站设计有什么影响?
目前的网站设计的、AI应用比较多的就是图片生成、AI挑图、文案生成,网站设计生成还没有很成熟,DeepSeek还没有图片生成,应用上只有文案生成可以用看看,其他都还要看未来的发展。〈延伸阅读:网页设计公司不会告诉你的5个真相〉
对AI市场有什么影响?
目前的AI市场大部分都是几家大厂的大语言模型(LLM)像是OpenAI GhatGPT、Google Gemini、Anthropic、Meta、Microsoft,少数几家开源AI公司 Hugging Face、Stability AI、EleutherAI,中国市场AI有百度、阿里巴巴、腾讯、华为,DeepSeek的出现无疑是打破OpenAI 、Google 、Meta、Microsoft 的高成本规则,将AI带入一个高CP值的市场如果真的是采用开源模式,那么DeepSeek将因为低价而抢下不少市场占比,对使用AI的企业与个人来说,成本降低绝对是一件好事,当然目前都只是推测,就让我们继续看下去吧。结论
DeepSeek的出现无疑为中文AI应用开启另一道门,在现有的AI应用下有机会取代OpenAI的大语言模型,但因为刚出来不久评价和商业模式还不明确,各大LLM都不能忽视DeepSeek的出现,DeepSeek的争议包含抄袭、资料、安全和政治等方面,不仅影响了DeepSeek 声誉,DeepSeek需要更积极面对这些争议,加强技术研发,提高产品安全性,并遵守相关法律法规,才能在竞争激烈的AI 市场中立足。 AI市场竞争越激烈,受益者肯定是使用AI的企业跟个人,不妨正面看待AI市场竞争与发展,停看听才是企业的最佳策略。〈延伸阅读:用ChatGPT写文案好吗?AI为SEO带来什么影响?〉
(本文为达文西数位科技所有,禁止转载图文)

