

大部分的網站都不需要限制搜尋引擎來爬取、索引資料,但如果有需要限制的時候,應該怎麼做呢?可以使用 robots.txt 跟 noindex 這兩個語法來限制搜索引擎,robots.txt 負責「限制爬取」,noindex 則負責「限制索引」,限制搜尋引擎基本上跟SEO沒有直接關係,但可以調配網站爬取與索引的資訊,讓網站的收錄內容更趨向一致,間接幫助了網站的SEO優化。
〈延伸閱讀:SEO是什麼? 簡單說讓你聽得懂〉
爬取(檢索)、索引哪裡不一樣?
「爬取」跟「索引」是搜尋引擎的兩個工作階段,搜尋引擎會先透過檢索器來「爬取」網站資料,也是俗稱的爬蟲程式,爬完網站之後才會把爬到的資料建立「索引」也就是「收錄」,而 robots.txt 就是一個告訴搜尋引擎「能不能爬取」的文字檔,noindex 則是一個告訴搜尋引擎「能不能收錄」的網頁語法,這兩個設定不能衝突,要彼此配合。
什麼情況下用 robots.txt?
搜尋引擎不是只有 Google,還有 Yahoo、Bing、Ahrefs、Baidu…,還有數以百千計的搜尋程式,網站如果是上千頁的網站,一直被抓取就會佔用網站資源 (流量、CPU、RAM),這時候就可以使用 robots.txt 來限制搜尋引擎來爬網站,網站可以用 robots.txt 選擇讓哪些引擎可以抓,哪些引擎不能抓,以調節網站負載,再來,如果網站有很多跟排名無關的檔案、影片,也不希望被抓取的就可以用拒絕爬取指令節省爬取成本,像是/downloads/、/videos/,千萬不要用 robots.txt 來拒絕爬取網站後台,像是 /admin/、/wp-admin/,你不設還好,一設定連駭客都可以透過 robots.txt 查詢你的網站後台網址,防止收錄應該用 meta robots,而不是 robots.txt。〈延伸閱讀:SEO工作內容是什麼?〉
什麼是「搜尋引擎的爬取成本」?
搜尋引擎對每個網站都有不同的「網站爬取時間」,並不是公平分配時間爬取,這個時間成本我們稱作「搜尋引擎爬取成本」,爬取時間是根據「Sitemap.xml」、「網站規模大小」、「網站權重高低」、「網站連結優化程度」、「連結健康程度」...,根據條件給予不同的爬取時間,希望排除對SEO沒幫助的內容被抓取,可以使用 robots.txt 進行排除。
〈延伸閱讀:Sitemap是什麼?一次搞懂網站地圖提交〉
什麼情況下用 noindex?
網站有不想被搜尋引擎收錄的網頁,像是網站後台網址、測試用網址、登入、註冊、結帳…,無論是什麼原因,只要不想被搜尋引擎收錄,就可以用 noindex 來限制索引(收錄),noindex在單一網頁撰寫在 meta 的語法,需要一頁一頁去寫,也可以用程式以單元方式自動產生,如果有更重要的網頁或檔案,會建議用密碼機制來保護檔案,因為設定 noindex 無法保證一定不收錄。
robots.txt 與 noindex 使用時機
| 項目 | robots.txt | noindex |
|---|---|---|
| 使用時機 | 限制爬取內容、降低主機負載 | 限制內容被索引(收錄) |
| 功能 | 告訴檢索器可以「爬取」哪些內容 | 告訴檢索器可以「收錄」哪些內容 |
| 缺點 | 只能限制爬取,無法限制收錄 | 被 robots.txt 限制後無法執行 |
| 撰寫方式 | robots.txt 撰寫後放到網站根目錄 | 將語法寫在 html 程式碼中 |
| 指令欄位 | User-agent Allow Disallow Crawl-delay Sitemap |
meta name content index noindex follow nofollow |
| 產生器 | 有 | 無 |
| 測試器 | GSC robots.txt 測試工具 | 無 |
如何撰寫 robots.txt?
寫 robots.txt 之前,必須先認識這五個指令欄位,以及常見的檢索器名稱,才能依照欄位去撰寫 robots.txt 文字檔,robots.txt 可以用各種文字編輯進行編輯,像是 Notepad、TextEdit、vi 、emacs、TextEdit、Sublime、Atom、Notepad++、Visual Studio Code...都可以喔。
5個指令欄位介紹
User-agent:填寫「檢索器字串」名稱 Allow:允許抓取的「網站內容的路徑」
Disallow:不允許抓取的「網站內容路徑」
Crawl-delay:設定檢索器爬取網站的「間隔秒數」
Sitemap:Sitemap 放置的網址路徑 (絕對網址)
常見搜尋引擎檢索器
| 搜尋引擎 | 檢索器字串 |
|---|---|
| Googlebot | |
| Yahoo | Slurp |
| Bing | bingbot |
| DuckDuckBot | DuckDuckBot |
| facebot | |
| Apple | Applebot |
常被擋的檢索器
| 搜尋引擎 | 檢索器字串 |
|---|---|
| Yandex | YandexBot |
| Majestic | MJ12bot |
| Ezooms | Ezooms |
| 百度 | Baiduspider |
| Ahrefs | AhrefsBot |
| MOZ | rogerbot |
| Semrush | SEMrushBot |
| Petalsearch | PetalBot |
| DotBot | DotBot |
robots.txt 要放在網站的根目錄
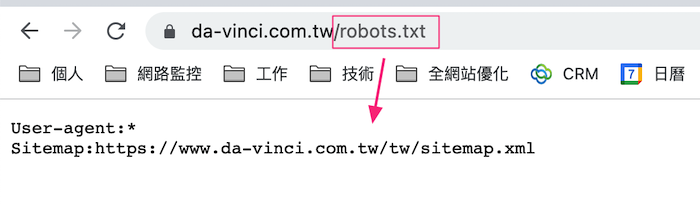
8個 robots.txt 範例
範例一: 允許所有的檢索器都可以來爬網站
User-agent: *
Disallow:
範例說明:「*」 就是全部檢索器,Disallow 「空值」代表「不拒絕」就是「允許」的意思,即使沒有放上 robots.txt 檔案,網站預設就是全部允許,但還是建議放。
範例二: 拒絕所有檢索器來爬取網站資料
User-agent: *
Disallow: /
範例說明:「*」 就是全部檢索器,Disallow:「/」代表根目錄,所有檔案都拒絕的意思。
範例三: 只允許Google的檢索器、Ads來爬取網站資料,其他檢索器都拒絕
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow:
User-agent: *
Disallow: /
範例說明:「Googlebot」 就是Google的「檢索器名稱」,Disallow 空值代表「允許」,「*」 就是全部檢索器,「/」則代表全部檔案,全部檔案都拒絕的意思。
範例四: 僅拒絕百度檢索器來爬網站資料,其他檢索器皆允許
User-agent: Baiduspider
Disallow: /
User-agent: *
Disallow:
範例說明:「Baiduspider」 就是百度的檢索器名稱,「/」代表所有檔案,所有檔案都拒絕的意思,「*」 就是全部檢索器,「Disallow: 空值」就是全部都允許的意思。
範例五:拒絕所有檢索器爬網站,只允許 Google 爬取 category 目錄。
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /category/
Disallow: /
範例說明:「*」 就是全部檢索器,「/」所有檔案,「Googlebot」就是Google的檢索器名稱,Disallow: / 全部拒絕的意思,Allow: /category/ 允許這個目錄名稱。
範例六: 不可以爬取有admin名稱網址、case-review.html、download 目錄下網址、封鎖全部.xls檔案
User-agent: *
Disallow: */admin/*
Disallow: /case-review.html
Disallow: /downloads/*
Disallow: /*.xls$
範例說明:「*」 就是全部檢索器的意思, 「*」也代表任意字元,「*/admin/*」代表有出現admin,* 就是無論出現是什麼字元,「$」代表特殊字串的網址,無論出現哪一種模式。
範例七: 所有的檢索器都以五秒作為抓取網站內容的時間間隔。
User-agent: *
Crawl-delay: 5
範例說明:「*」 就是全部的意思,每5秒抓一次,1000頁就是5000秒,5000秒,就是指1.3小時可以抓完1000頁,設定抓取時間可以紓緩主機的負載,特別是大型網站。
範例八: 允許所有檢索器來抓網站,告訴索引器 Sitema.xml 檔案在哪個位置。
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml
範例說明:「*」 就是全部的意思,「/」所有檔案,告訴爬蟲程式網站的 Sitemap 檔案放在 http://www.example.com/sitemap.xml。
robots.txt 的6個注意事項
robots.txt 無法阻擋收錄
robots.txt 雖然限制了 Google 來抓取網站,但如果別人的網站放了你設定限制的連結,一樣會被 Google 抓取並收錄,所以 robots.txt 是無法限制搜尋引擎收錄的,要限制收錄要用noindex 而不是用 robots.txt。
要有網站根目錄的上傳權限
robots.txt 檔案做好之後,只能傳到網站的根目錄,放到其他目錄都是無效的,只能放在 https://www.domain.com/robots.txt,如果你沒有上傳根目錄的權限,就無法使用 robots.txt ,要請網站設計公司幫忙放置,如果是 Wix、Wordpress 之類的網站,可以透過網站後台去編輯 robots.txt 檔案。
並非所有檢索器的語法都一樣
大部分的搜尋引擎都會依照 robots.txt 指令,但不是每一個搜尋引擎都是看得懂 robots.txt 語法,因此要對不同搜尋引擎使用語法,如果只針對知名的進行限制或允許因此要對不同搜尋引擎使用不同語法,如果只針對常見的的幾個搜尋引擎,那 robots.txt 基本語法已經很足夠了。
robots.txt 格式有限制
網站的 robots.txt 只能有一個,而且名稱只能是 robots.txt,一字不漏,且只能用小寫不能用大寫,robots.txt 檔案大小限制 500K 以內,只能用 UTF-8 編碼的純文字檔案,每行須以 CR、CR/LF 或LF 分隔,撰寫完成後可用 robots.txt 測試工具去測試 robots.txt 寫法是否正確。
robots.txt 可以指定多種型態
robots.txt 不是只有限制抓取網頁,還可以限制檔案、照片、影片…。
robots.txt 要避免跟 noindex 衝突
假設robots.txt 設定了abc.html 不抓取,又在abc.html 中設定不收錄 (noindex),這樣就會產生衝突,因為 robots.txt 設定abc.html 不抓取,造成 Google 爬蟲找不到abc.html 中的不收錄 noindex 的語法,如果有別的網站放置這個 abc.html 網址,就會造成收錄,這時候只要把 robots.txt 的 abc.html 不抓取的指令移除,就可以化解衝突。
robots.txt 產生器
如果你不想打字,可以試試看 robots.txt 的產生器,但記得要移除第一行的「robots.txt generated by www.seoptimer.com」,將產生的 robots.txt 檔案放到網站的根目錄,再用測試工具測試一下語法的正確性。
【工具連結:SEOptimer】
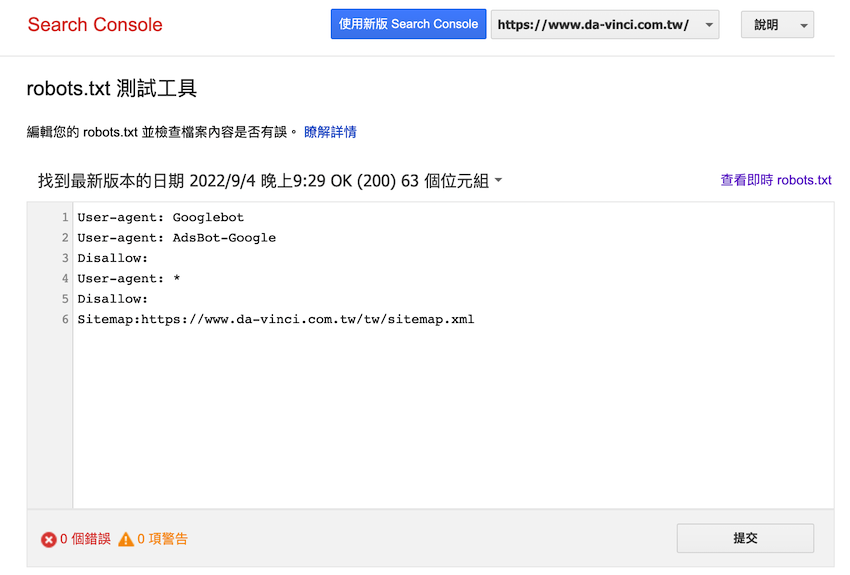
robots.txt 測試工具
robots.txt 文件做好之後,要上傳到網站的根目錄,可以用 Google Search Console (GSC) 的 robots.txt 測試工具對文件進行驗證,robots.txt 測試工具可以檢查指令是不是可以正常運作,如果在 robots.txt 有設定限制某些檢索器抓取,測試工具就會顯示錯誤與警告資訊。
【工具連結:robots.txt 測試工具】
檢查 robots.txt 是不是正確
如何撰寫 noindex?
noindex 是一個 html 的 meta 中繼標記,通常會寫在每個網頁 html 的 <head> 標籤中,所以必須要有編輯網頁 <head> 的權限,如果沒有權限就只能請網頁設計公司幫忙設定,如果是 Wix、Wordpress 之類的 CMS 網站,可以從後台修改 <head> 中繼標記,也可以單元方式用程式自動寫入,寫 noindex 之前,必須先認識這五個指令欄位。
noindex 的5個指令欄位
meta name:檢索器名稱content:內容標籤
index:允許網頁索引(收錄)
noindex:拒絕網頁索引(收錄)
follow:允許 Google 爬蟲爬這個網頁的所有連結
nofollow:拒絕 Google 爬蟲爬這個網頁的所有連結
noindex 是寫在網頁 html 裡面

5個 noindex 範例
範例一: 拒絕所有搜尋引擎收錄網頁
<html>
<head>
<meta name="robots" content="noindex">
</head>
</html>
範例二:拒絕 Google 檢索器收錄網頁
<html>
<head>
<meta name="googlebot" content="noindex">
</head>
</html>
範例三:拒絕所有搜尋引擎收錄網頁,並拒絕爬所有連結
<html>
<head>
<meta name="robots" content="noindex, nofollow">
</head>
</html>
註:如果是 <meta name="robots" content="noindex,nofollow"> ,可寫成 <meta name="robots" content="none">
範例四:允許所有搜尋引擎收錄網頁與追蹤所有連結
<html>
<head>
<meta name="robots" content="index, follow">
</head>
</html>
說明:如果是 <meta name="robots" content="index,follow"> ,可寫成 <meta name="robots" content="all">
範例五: 拒絕所有檢索器追蹤網頁的所有連結,且拒絕 Google 檢索器收錄網頁
<html>
<head>
<meta name="robots" content="nofollow">
<meta name="googlebot" content="noindex">
</head>
</html>
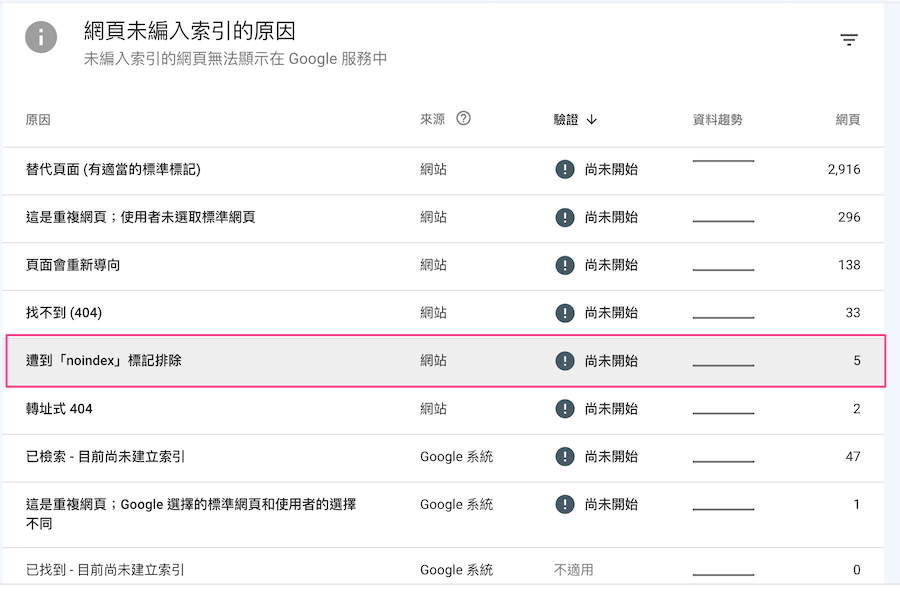
如何查詢被 noindex 的網頁?
可以從 Google Search Console 的「索引」的「網頁」單元去看是不是有被 noindex 的網頁,這些網頁是不是預設要限制收錄的網頁,如果網址清單沒錯就不需要變動,如果有設定錯誤的 noindex,就要將網頁的語法移除,並且重新要求索引網頁。
檢視 noindex 的網頁
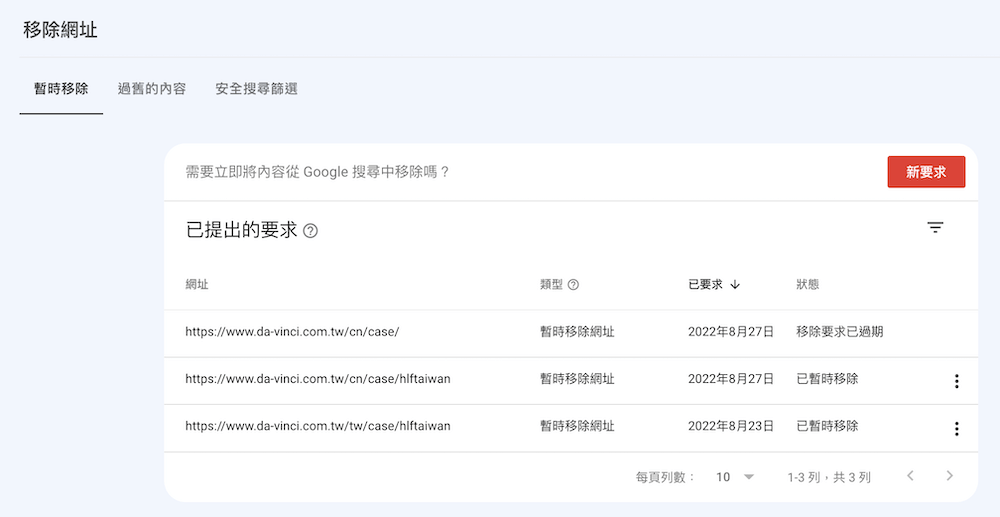
如何移除已經被 Google 收錄的網址?
如果有被收錄到不想被收錄的資料該怎麼辦呢?其他的搜尋引擎就不知道該怎麼移除,但如果是Google的話,在 Search Console 有一個移除網址的功能,可以暫時移除6個月,在這期間可以去設定網頁的 noindex 語法,就可以讓網頁不再被收錄。
Google Search Console 移除網址功能
結論
一般網站很少需要去限制搜尋引擎的爬取(檢索)、索引(收錄),但如果真的有需要就可以使用 robots.txt 跟 noindex 這兩個語法來限制搜索引擎,用 robots.txt 設定檢索器的「限制爬取」,用 noindex 設定搜尋引擎的「限制收錄」,如果想移除 Google 已經收錄的網址,可以用 Google Search Console 的移除網址功能將網站移除,但還是要設定 noindex,不然6個月後還是會被 Google 收錄,如果不會操作,可以找網頁設計公司幫忙操作。
〈延伸閱讀:網頁設計公司不會告訴你的5個真相〉

